複数のCSVファイルをPythonで1つのExcelファイルにまとめることができます。
その流れをまとめてみました。
CSVファイルを1つにまとめたい
ネットで明細を見ることができる場合、ほとんどはCSVファイルをダウンロードできます。CSVファイルをダウンロードできないサービスは、利用しないほうがいいくらいです。
で、月ごとにダウンロードできる場合、1年間で12個のファイルです。これを1つのファイルにまとめたいというのが今回のはなし。
複数のCSVファイルのデータを1つのシートにまとめるというのは、過去に記事にしています。
複数のCSV(会計データ)やExcelファイルを1つにまとめる(結合する)方法 Excelの「取得と変換」 | GO for IT 〜 税理士 植村 豪 OFFICIAL BLOG
複数の会計データ(CSVファイル)を1つのシートにまとめる方法(バッチファイル編) | GO for IT 〜 税理士 植村 豪 OFFICIAL BLOG
やり方はいろいろありますが、今回はPythonを使って特定の場所(inbox)にあるファイルを月ごとにシートをわけて
Excelファイルで書き出す(CSVだとシート1つしか保存できないため)という前提です。
Pythonを利用するには
ても、Pythonをパソコンにインストールしないことにははじまりません。
Macならターミナル、Windowsならコマンドプロンプトという標準のアプリがあります。次のように入力してPythonがインストールされているかどうかを以下のように入力して確認してみましょう。
python3 --versionもし、インストールされていないようならインストールしましょう。(現状だと3.13.0)
Pythonインストール
https://www.python.org/downloads
そして、仮想環境(パソコンの環境とは別でPython用の環境)をつくっておきます。venv(ブイエンブ)というのがそうです。
あとは、今回のしくみをつくるのにデータ処理の「Pandas]とExcelに書き込むための「xlsxwriter」という2つのライブラリが必要になります。これもインストールしておきましょう。
pip3 install pandaspip3 install xlsxwriterそのうえで、以下のPythonのコードをテキストエディタ(メモ帳)などに書いていきます。コードはChatGPTに聞けば教えてくれます。エラーが出たときにはすぐに聞いてみましょう。
一応、わたしがChatGPTに教えてもらいながら、書いたコードを置いておきます。気になる方は開いてもらえれば。
今回書いたPythonコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
import os import subprocess import sys # 仮想環境のパス venv_dir = os.path.join(os.path.dirname(__file__), ".venv") # 仮想環境の作成とPandasのインストール if not os.path.isdir(venv_dir): subprocess.run([sys.executable, "-m", "venv", venv_dir]) subprocess.run([os.path.join(venv_dir, "bin", "pip"), "install", "pandas"]) # 仮想環境のPython実行ファイルのパス python_executable = os.path.join(venv_dir, "bin", "python") # 仮想環境内で処理を実行 subprocess.run([python_executable, "-c", """ import pandas as pd import glob import os import re # CSVファイルが保存されているディレクトリのパスを指定 csv_files_path = '/元のCSVファイルを置いてあるパス/*.csv' all_files = glob.glob(csv_files_path) # ファイル名から年月を抽出、文字列→数値で昇順にソート def extract_year_month(filename): match = re.search(r'(\\d{4})(\\d{2})', os.path.basename(filename)) if match: year = int(match.group(1)) month = int(match.group(2)) return year * 100 + month # YYYYMM形式の数値に変換してソート return float('inf') # マッチしない場合は最後に並ぶようにする all_files = sorted(all_files, key=extract_year_month) # ExcelWriterを使用して新しいExcelファイルを作成 output_excel_path = 'Excelファイルを保存したい先のパス/mix_CSV.xlsx' with pd.ExcelWriter(output_excel_path, engine='xlsxwriter') as writer: workbook = writer.book for file in all_files: # シート名をファイル名から生成(拡張子を除く) sheet_name = os.path.splitext(os.path.basename(file))[0] # ファイルを読み込み、各行をリストとして保持 with open(file, 'r', encoding='shift_jis') as f: lines = f.readlines() # 各行をカンマで分割し、データフレームに変換 data = [line.strip().split(',') for line in lines] df = pd.DataFrame(data) # 列ごとに数値変換(エラー時はそのまま保持) for col in df.columns: try: df[col] = pd.to_numeric(df[col]) except ValueError: pass # 変換できない場合はそのまま # データフレームをExcelシートに書き込み df.to_excel(writer, sheet_name=sheet_name, index=False, header=False) """]) |
コードをテキストエディタに書いた後、保存しましょう。末尾を「.py」とします。たとえば、「CSV_mix2.py」のように。
ファイル名が「.py.txt」のように表示された場合は、ファイル名の変更で「.py」にすれば大丈夫です。
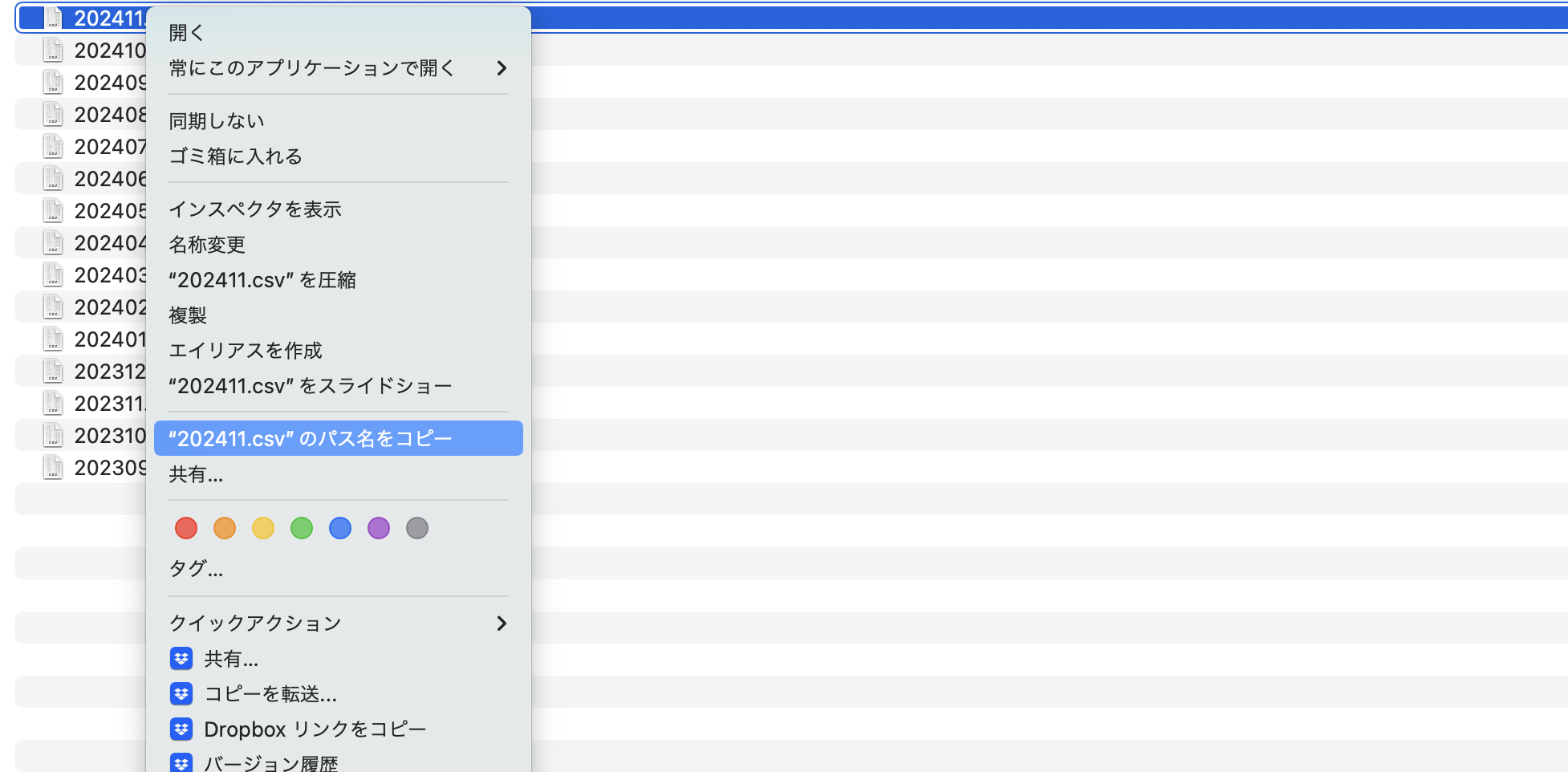
元データを置いておく場所を決めておきましょう。「パス」はファイルを右クリックしてoptionキーをクリックすると、パス名のコピーができます。それが「元のCSVファイルを置いてあるパス」になります。
|
1 2 3 |
# CSVファイルが保存されているディレクトリのパスを指定 csv_files_path = 'Excelファイルを保存したい先のパス/mix_CSV.xlsx' all_files = glob.glob(csv_files_path) |
CSVのファイル名は年月ごとに違うので「*(ワイルドカード).csv」としてcsvファイルであれば、すべて対象にしています。
ちなみに、このファイルをまとめても、年月順には並びません。なぜなら、「202411.csv」はファイル名で数字でなく文字列のデータとして認識されているからです。
なので、ファイル名から年月のデータを抽出して数字に変換、それを昇順に並べることになります。それを以下で書いています。
|
1 2 3 4 5 6 7 8 9 10 |
# ファイル名から年月を抽出、文字列→数値で昇順にソート def extract_year_month(filename): match = re.search(r'(\\d{4})(\\d{2})', os.path.basename(filename)) if match: year = int(match.group(1)) month = int(match.group(2)) return year * 100 + month # YYYYMM形式の数値に変換してソート return float('inf') # マッチしない場合は最後に並ぶようにする all_files = sorted(all_files, key=extract_year_month) |
あとは、「xlsxwriter」で12個のファイルを読み込んで、「,(カンマ)」で区切ってデータリストにしておき、それをExcelファイルに書き込んで保存するという流れです。
|
1 2 3 4 |
# ExcelWriterを使用して新しいExcelファイルを作成 output_excel_path = 'Excelファイルを保存したい先のパス/mix_CSV.xlsx' with pd.ExcelWriter(output_excel_path, engine='xlsxwriter') as writer: workbook = writer.book |
Excelファイルの保存場所を「’Excelファイルを保存したい先のパス/mix_CSV.xlsx’」で決めましょう。パスの指定は先程と同じように。同じ場所なら全く同じパスで大丈夫です。
今回は同じ場所に「mix_CSV」という名前で保存します。
ターミナル(コマンドプロンプト)でPythonファイルが動くかどうかを試してみましょう。以下のように入力すると、
|
1 2 |
python3 /Users/gouemura/Library/CloudStorage/Dropbox/Python/CSV_mix2.py # python3 /Pythonファイル(CSV_mix2.py)を置いてあるパス |
「mix_CSV.xlsx」というExcelファイルができているのがわかります。
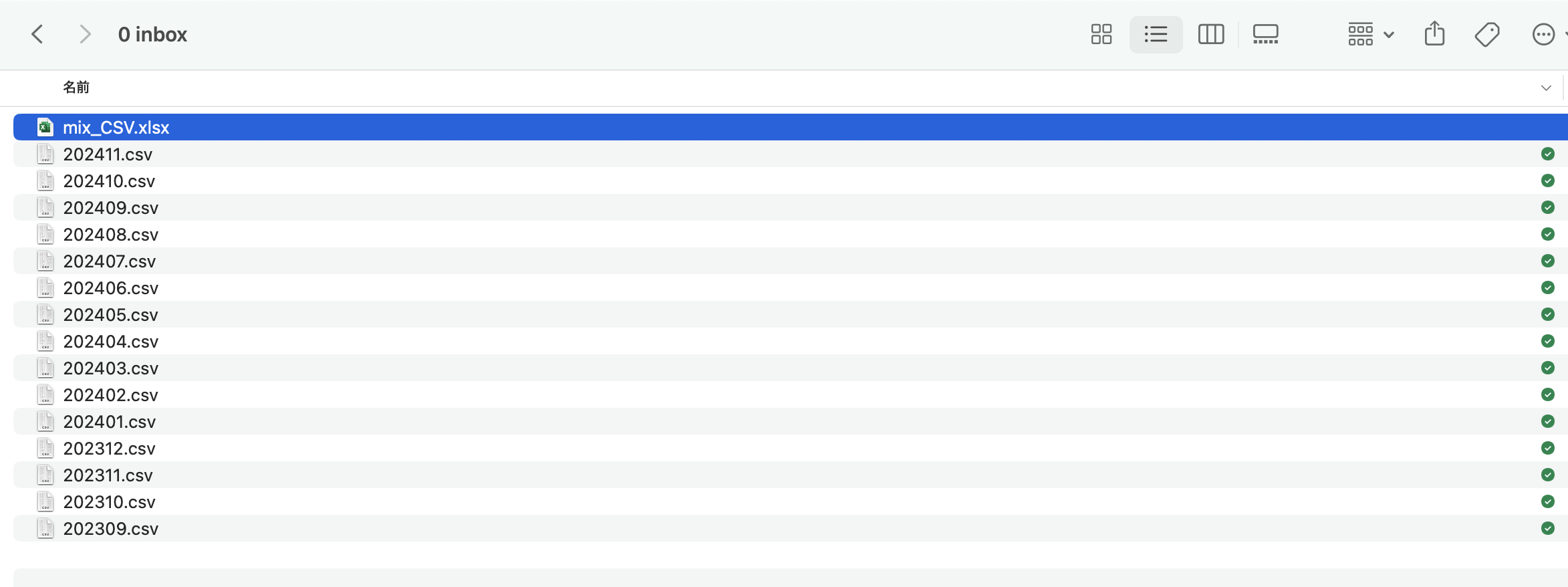
ファイルを開くと、データも年月別にシート別に反映されているのがわかります。
ターミナルでPythonファイルを動かしてこの処理を完了するのにかかった時間は1秒です。動画にしてみました。シートのコピペでやっていたら、1秒は無理でしょうね。
Macでファイル検索してワンクリック
Macの場合、「Autometer」があるので、使ってみるのもおすすめです。
Finderのアプリケーションにある「Automator」から、Pythonファイルを動かすことができます。
「Automator」を起動して、「アプリケーション」をクリックし、「選択」をクリック(訂正したい場合には左下の「既存の…」をクリック)し、
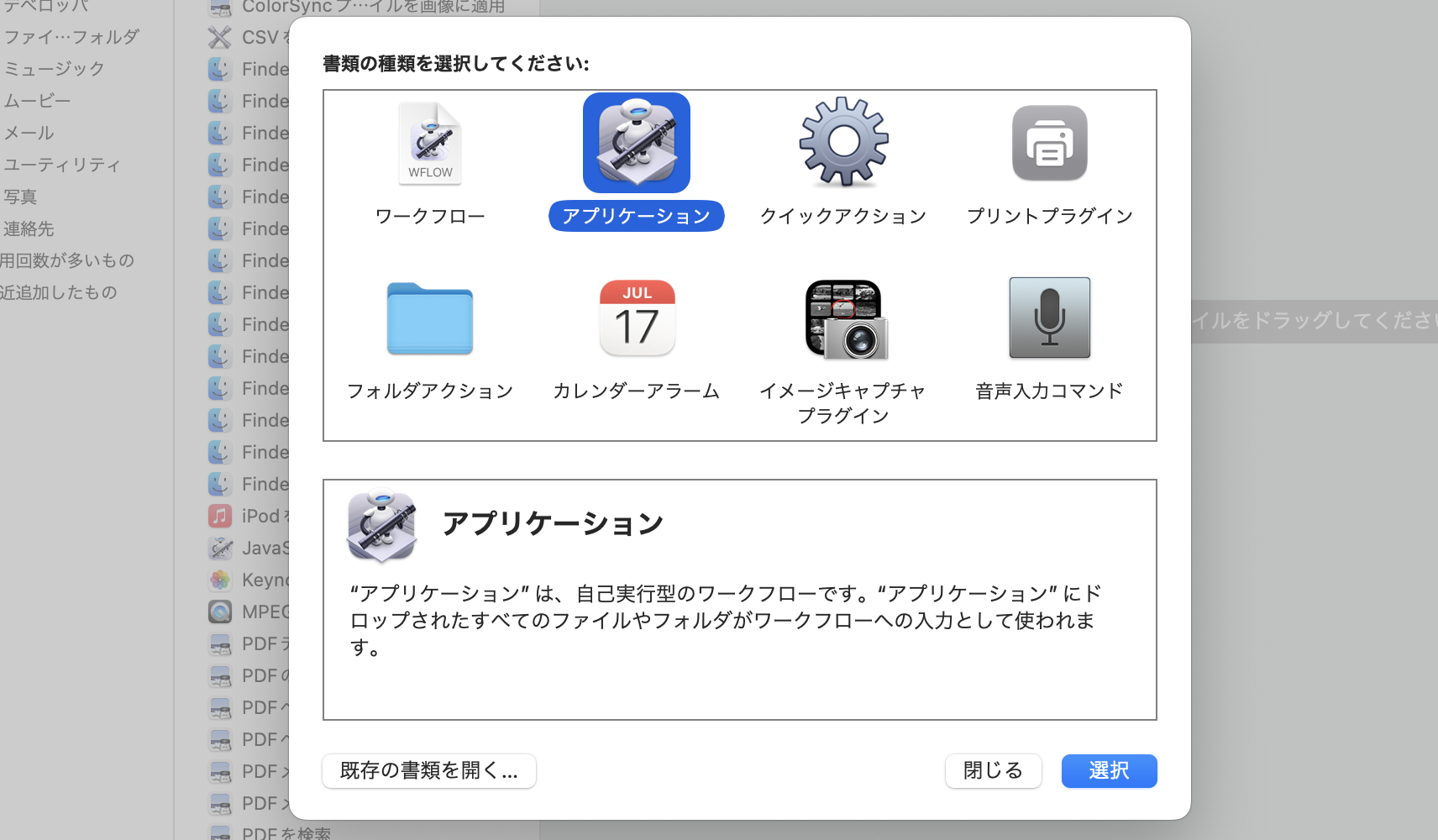
「シェルスクリプトを実行」を検索しましょう。
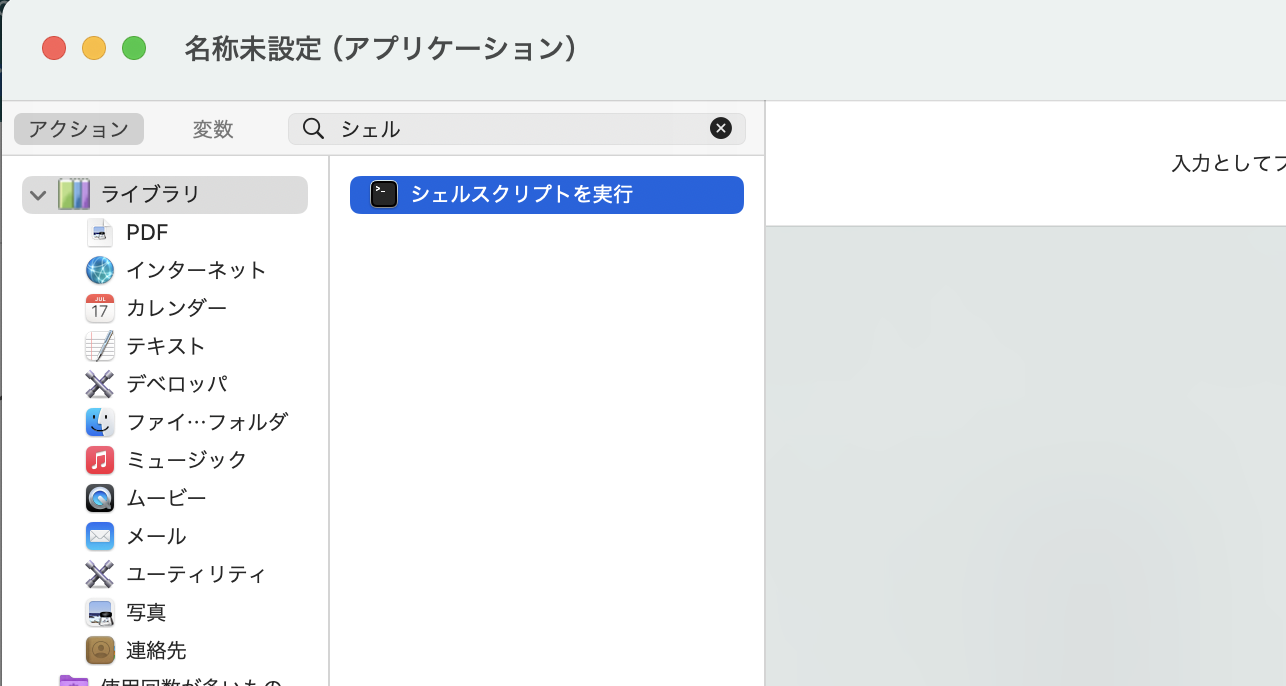
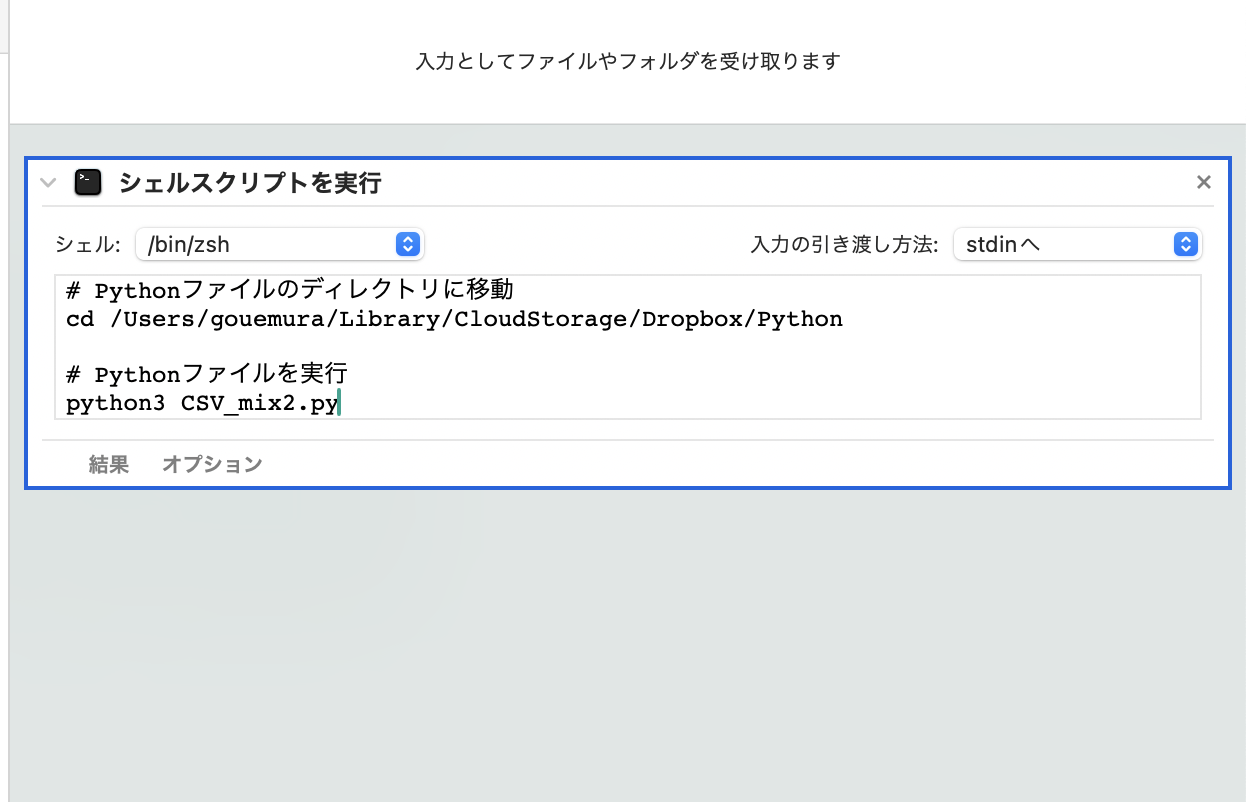
白い枠のところにPythonを動かすコマンドを入力しましょう。
|
1 2 3 4 5 |
# Pythonファイルのディレクトリに移動 cd /Users/gouemura/Library/CloudStorage/Dropbox/Python # Pythonファイルを実行 python3 CSV_mix2.py |
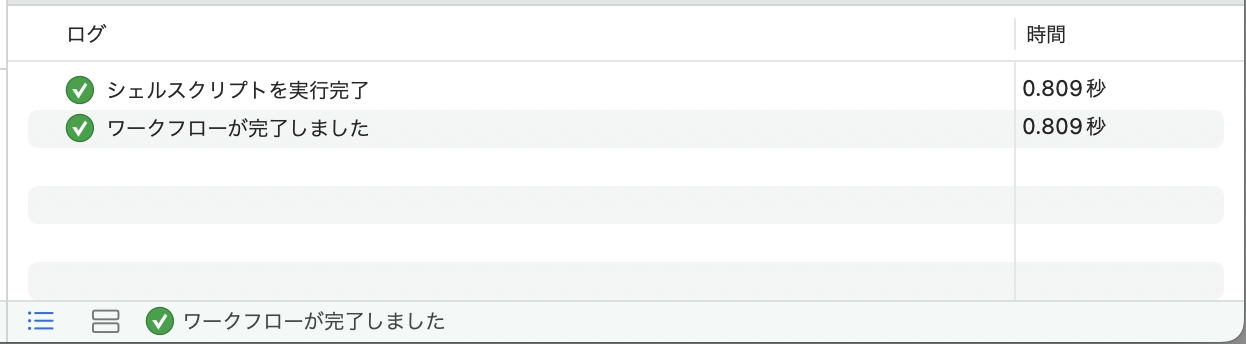
上手くいけば、下の画面にログが表示されます。
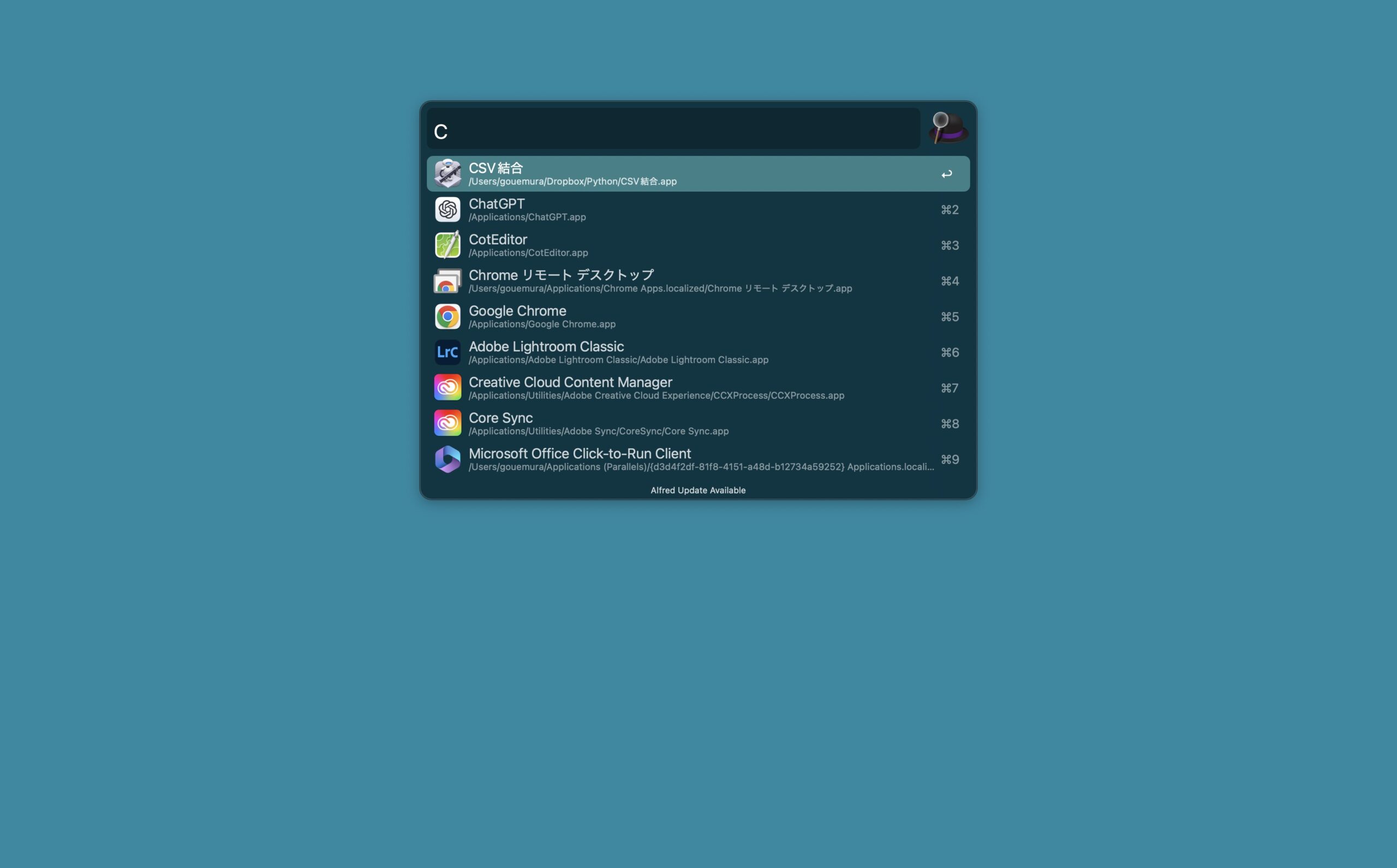
このアプリを検索で呼び出せるようにしておけば「c」→「Enter」で動かせます。
ということで、複数のCSVファイルをExcelファイルにまとめる流れ。これに限らず応用できることもあると思うので参考にしていただければ。
ChatGPTを上手く使うとコードの書き方やエラーの原因もわかりますし、何ができるかもわかってプログラミングのいい練習になります。
気になったものは、試してみましょう。
追記:2024/12/7 PDFファイルを分割するPythonはこちらの記事に書いてあります。
PythonでPDFファイルを分割する流れ。 | GO for IT 〜 税理士 植村 豪 OFFICIAL BLOG
【編集後記】
昨日は税理士業、セミナー企画、夕方に近所の体育館で開催されたパーソナル体験会に行こうとしたのですが予約がないといけなく、かつ電話というのであきらめました。その代わりに洗車を。夜はゼルダを長男(9)といっしょにやってクリアまで。予想通りの当たりゲームでした。
【昨日の1日1新】
※「1日1新」→詳細はコチラ
サントリー 天然水ヨーグルスカッシュ